| Tornado
Codes A code C(B) is defined as a set of n message bits and b n check bits that are associated with a bipartite graph B. The graph B has n left nodes and b n right nodes, corresponding to the message bits and the check bits respectively. The encoding consists of computing each check bit as the sum of the bits of its neighbors in B. The encoding time is proportional to the number of edges in B. If the value of a check bit is known and all but one of the message bits associated with that check bit is known, the missing message bit can be found by computing the sum of the check bit and its known message bits. 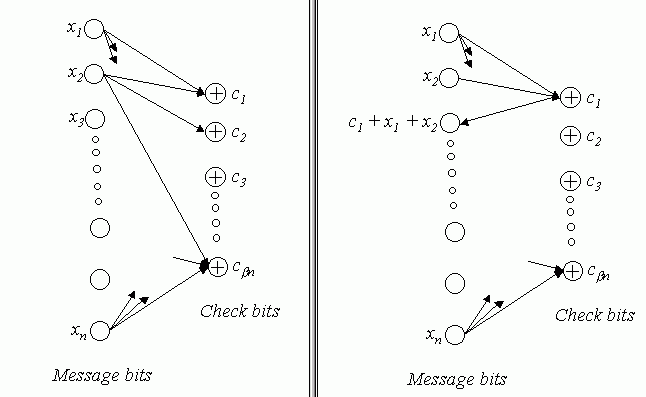 Fig1
Graph representation of one stage of the Tornado Code. (Fig from Practical
Loss-Resilient Codes, by Michael Luby, Michael Mitzenmacher, Amin Shokrollahi,
Daniel Spielman and Volker Stelmann)
Encoding and decoding are simple XOR operations on bits or packets. The total decoding time is proportional to the number of edges in the graph. From the above diagram it is clear that at most one message bit that contributes to a particular check bit or the check bit itself, can be lost if the code is to be recovered. To produce codes that are more loss resilient, the basic structure is cascaded to form the cascaded code C(B). The first structure produces b n check bits for the original n message bits and at the next stage a similar structure is used to produce b 2 n check bits for the b n check bits. At the final stage a conventional loss resilient code such as Reed- Solomon or BCH code is used. The final code would resemble the following diagram: 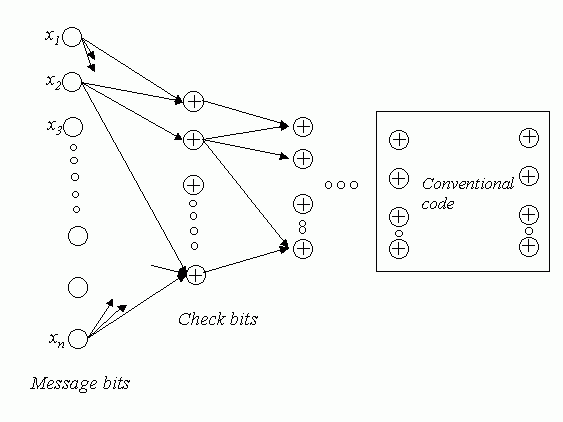 Fig2
Graph representation of the complete code. (Fig from Practical Loss-Resilient
Codes)
The number of stages and the basic structure of the bipartite graph involve a very complicated design procedure based on differential equations that are beyond the scope of this project. An implementation of the Tornado code developed by Jeffrey Considine was used to explore the possibility of the use of these codes in data synchronization. |