



Next: Putting it together
Up: Scalability in Mobile Device
Previous: SyncML
Contents
There are many instances of data synchronization when there is a
need to synchronize very similar data present on different hosts.
CPISync [26,13] makes the time complexity of this
synchronization almost independent of the size of the data sets
being synchronized and only dependent on the number of differences
between the two data sets, thus approaching the lower information
theoretic bounds of Equation 2.1.
This is in marked contrast to Slowsync which utilizes a wholesale
data transfer between hosts while synchronizing data, making data
synchronization time linear in the number of records in the
database.
CPISync, which is based on a recent solution to the set
reconciliation problem [14] by Minsky,
Trachtenberg and Zippel is scalable both with the number of
devices in the network and the size of the databases being
synchronized. Though this solution involves more computation as
compared to Slowsync, the computation can be distributed
asymmetrically between the hosts. This means that in case there
are hosts with different computational capabilities (e.g. PC and a
PDA), CPISync can transfer most of the computation to the PC, thus
allowing for quicker execution of CPISync as compared to a
symmetric approach.
Figure 2.7:
CPISync scales perfectly with increasing number of
records in the database, while the Slowsync time increases
linearly with growing number of records. CPISync time grows
quickly with increasing differences between the synchronizing
databases.
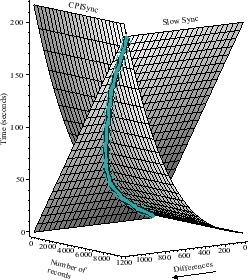 |
Figure 2.7 shows the times taken by CPISync and
Slowsync to synchronize data sets of varying sizes and differences
on a PC-PDA synchronization system. The time complexity is the sum
of the communication time of transferring data between the two
hosts and the computational complexity of synchronization for
CPISync and Slowsync. Slowsync is completely unscalable with
increasing data set sizes due to its linear dependence on the size
of data sets being synchronized unlike CPISync which takes
constant time for a given number of differences irrespective of
the data set sizes.
In a PC-PDA synchronization setting the number of differences
between successive synchronizations usually does not exceed a few.
For example, in an address book of 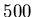 addresses, it is unlikely
that a user will add or more than
addresses, it is unlikely
that a user will add or more than 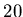 new addresses in a week. In
such instances, the case for using CPISync is particularly strong,
since for a small number of differences, the CPISync algorithm
outperforms Slowsync significantly.
We discuss the CPISync algorithm in detail in Chapter 3.
new addresses in a week. In
such instances, the case for using CPISync is particularly strong,
since for a small number of differences, the CPISync algorithm
outperforms Slowsync significantly.
We discuss the CPISync algorithm in detail in Chapter 3.
Next: Putting it together
Up: Scalability in Mobile Device
Previous: SyncML
Contents
Sachin Kumar Agarwal
2002-07-12