Next: Practical considerations Up: Applications Previous: Code engineering Contents
Specifically, we may arbitrarily delete a generator of
![]() and replace it with a trellis-oriented generator. Because of
Theorem 2.3 we know that the resulting code will have
trellis complexity and code parameters (e.g. length, minimum distance)
no worse than the original code.2.2
and replace it with a trellis-oriented generator. Because of
Theorem 2.3 we know that the resulting code will have
trellis complexity and code parameters (e.g. length, minimum distance)
no worse than the original code.2.2
In fact, this method may be applied to several generators: shorten
![]() by deleting k generators; replace the generators with k
trellis-oriented generators. This allows us to create an amalgam of
the original code and a trellis-oriented code. Though the resulting
code is not guaranteed to match the decoding performance of our
original code, it often performs much better as we see in the
following example.
by deleting k generators; replace the generators with k
trellis-oriented generators. This allows us to create an amalgam of
the original code and a trellis-oriented code. Though the resulting
code is not guaranteed to match the decoding performance of our
original code, it often performs much better as we see in the
following example.
It requires 215 = 32, 768 trellis states and 262, 139 steps for Viterbi decoding. Figure 2.10 shows the dramatic improvement of this code as more generator vectors are replaced with trellis-oriented generators.
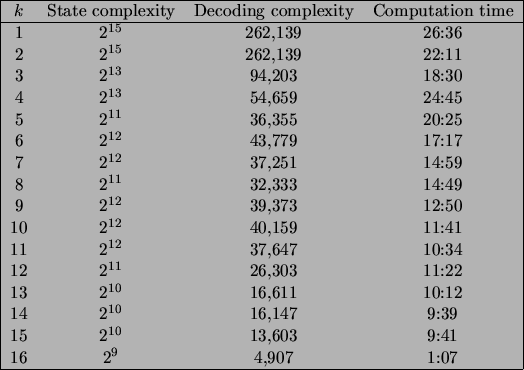 |
We note that both the state and decoding complexities generally decrease as k increases. Moreover, the computation time also generally decreases because of the decreasing size of the seed code.
http://people.bu.edu/trachten