Next: Trellis-bounded lexicodes Up: Instances of the G-construction Previous: Lexicodes Contents
We now consider a different generating mapping for the G-construction which will generate families of codes oriented towards a reduced decoding trellis.
There is a unique, minimal [45], trellis for an arbitrary
linear block code. Known as the BCJR [3] trellis, it
has no more edges or vertices at each time index than any other
trellis for the code and can be constructed fairly easily [35,43].
It is shown in [35,43] that the
minimal span generator matrix (MSGM) for a linear code, in which the
sum of the spans of the binary generators is minimized, reflects the
properties of the corresponding BCJR trellis. Namely,
if G is an MSGM of a code
![]() , comprised of the generators
g1,..., gk, then the number of vertices Vi and edges Ei in
the corresponding BCJR trellis is given by:
, comprised of the generators
g1,..., gk, then the number of vertices Vi and edges Ei in
the corresponding BCJR trellis is given by:
| pi | = | | |
|
With a minor modification of the lexicographic construction we may
exploit the above relations to locally minimize two measures of trellis
complexity: state complexity, which is the maximum number of states at
any time interval of the trellis, and Viterbi decoding complexity.
Specifically,
![]() is such a family of codes, and
it locally minimizes trellis complexity if
is such a family of codes, and
it locally minimizes trellis complexity if
![]() returns the vector with
maximum distance from
returns the vector with
maximum distance from
![]() whose bitwise reverse is lexicographically
earliest. For example, if the vectors {1011, 1101, 1110} are at
maximum distance from a code
whose bitwise reverse is lexicographically
earliest. For example, if the vectors {1011, 1101, 1110} are at
maximum distance from a code
![]() , then
, then
![]() returns the vector 1110. Because of their locally minimal trellis
complexity, these codes
may be justly called ``trellis-oriented.''
returns the vector 1110. Because of their locally minimal trellis
complexity, these codes
may be justly called ``trellis-oriented.''
Theorem 2.3 establishes that
![]() locally
minimizes trellis complexity among local extensions with optimal code
parameters. It is possible to improve Viterbi decoding complexity by
using a generating mapping which produces a longer extension, but the
information rate of the resulting code will be inferior.
locally
minimizes trellis complexity among local extensions with optimal code
parameters. It is possible to improve Viterbi decoding complexity by
using a generating mapping which produces a longer extension, but the
information rate of the resulting code will be inferior.
Proof. Suppose that G is an MSGM for the (n, k, d ) code
![]() whose
past and future subcodes have dimensions pi and fi
respectively, and whose trellis has vertices Vi and edges
Ei, i+1 at the i-th time interval. Now, consider appending
to G the generator
v =
whose
past and future subcodes have dimensions pi and fi
respectively, and whose trellis has vertices Vi and edges
Ei, i+1 at the i-th time interval. Now, consider appending
to G the generator
v = ![]() 1
1![]() |
|![]()
![]() as in
Equation (2.2) of the definition of the
G-construction. The generated code
as in
Equation (2.2) of the definition of the
G-construction. The generated code
![]() will have
parameters
will have
parameters
![]() . Without loss of
generality we may assume that the resulting generator matrix of
. Without loss of
generality we may assume that the resulting generator matrix of
![]() is an MSGM.
If we denote the difference in lengths between
is an MSGM.
If we denote the difference in lengths between
![]() and
and
![]() by
by
![]() n = n' - n, then a simple analysis shows that
n = n' - n, then a simple analysis shows that
![]() will have
past and future subcode dimensions:
will have
past and future subcode dimensions:
We may then use (2.6) and (2.7) at
each time unit i to compute the number of vertices and edges
(
| V'i|,| E'i|) in the BCJR trellis for
![]() based on the
vertices and edges (
| Vi|,| Ei|) in the BCJR trellis for
based on the
vertices and edges (
| Vi|,| Ei|) in the BCJR trellis for
![]() :
:
It is now a simple matter of algebra to compute the difference in
Viterbi decoding complexities between the trellises of
![]() and
and
![]() :
:
Since
| Ei| ![]() | Vi| for all i, minimizing the change in
Viterbi decoding complexity depends on minimizing
R(v) = R
| Vi| for all i, minimizing the change in
Viterbi decoding complexity depends on minimizing
R(v) = R![]() 1
1![]() |
|![]()
![]() , which in turn depends on having the
1 bits of
, which in turn depends on having the
1 bits of ![]() as far to the left as possible. On the other
hand,
as far to the left as possible. On the other
hand, ![]() cannot have weight less than the covering radius
cannot have weight less than the covering radius
![]() of
of
![]() if it is to produce an extension of shortest length.
Thus, the mapping
if it is to produce an extension of shortest length.
Thus, the mapping
![]() is one of several mappings which
meet both criteria for local optimality: minimizing R(v) and having
is one of several mappings which
meet both criteria for local optimality: minimizing R(v) and having
![]() .
On the other hand, other intuitive generating mappings, such as
picking lexicographically latest vectors at maximum distance
from the code, are not always locally
optimal.
.
On the other hand, other intuitive generating mappings, such as
picking lexicographically latest vectors at maximum distance
from the code, are not always locally
optimal.
Equation 2.8 also proves that minimizing
![]() is the
appropriate criterion for minimizing state complexity. This is
because larger values of
is the
appropriate criterion for minimizing state complexity. This is
because larger values of
![]() correspond to doubling more vertices
| Vi-
correspond to doubling more vertices
| Vi-![]() n| when generating Vi'.
Thus,
n| when generating Vi'.
Thus,
![]() locally minimizes state complexity as well.
locally minimizes state complexity as well.
width4pt depth2pt height6pt
Note that (2.8) and (2.9) provides us with a simple alternate method for computing the Viterbi decoding complexity or state complexity of any trivially-seeded G-code given its MSGM.
 |
1. for v = (v1, v2, v3,..., vn)do
2. fori from 1 to n
3. ifis a 1 then
4. vv + Gi
5. store the modified v;
6. among all stored v, return the lexicographically earliest
The proof of correctness and complexity for Method 2.4 follows trivially from the proof of Method 2.2.
http://people.bu.edu/trachten

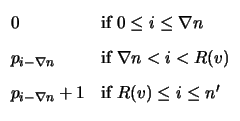
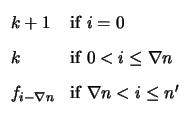
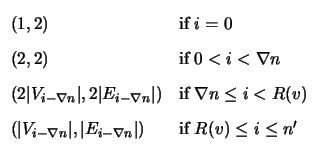
![\begin{displaymath}\begin{split}\Delta(Viterbi decoding complexity) &= (2\vert E...
...torname{R}}(v)-\nabla n - 1} \vert V_i\vert \right] \end{split}\end{displaymath}](img178.png)