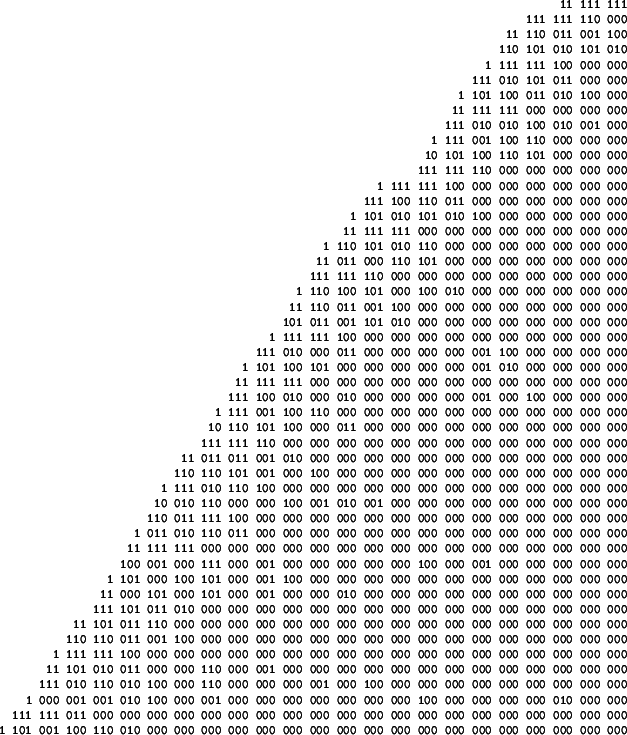Next: Applications Up: Lexicographic Codes Previous: Bounding Length Contents
Theorem 2.5 can be directly translated into an algorithm that computes G-families. The algorithm simply computes the coset leaders of G-codes in the family, from which the remaining parameters may be easily deduced. This computation scheme has the advantage of being dependent on the co-dimension (i.e. the dimension of the dual code) rather than the dimension or the length alone. Thus, this algorithm is efficient for high-rate codes, and it is presented in Algorithm 2.12.
In Algorithm 2.12 we reuse our earlier notation that
An oracle is simply a black box that computes a given function in constant time. In this case, we assume the existence of an oracle for computing the generating mapping because the complexity of such a computation can vary greatly among mappings. The proof of Lemma 2.13 follows from a straightforward analysis of the pseudo-code for Algorithm 2.12.
Proof. At each iteration, Algorithm 2.12 stores the coset
leaders of the code
![]() which it is computing and the companion
of each leader. Thus, the algorithm requires space
which it is computing and the companion
of each leader. Thus, the algorithm requires space
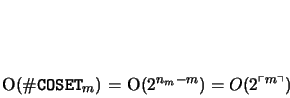
The time bound for this algorithm, on the other hand, is somewhat more
complicated. Consider the innermost loop of the algorithm during
the computation of the i-th extension.
Clearly, based on Theorem 2.5, lines 6-10 are
executed at most once for each coset of
![]() . Moreover, the
companion calculation in line 5 is executed once for each coset of
. Moreover, the
companion calculation in line 5 is executed once for each coset of
![]() . The companion may be determined with a binary search
over coset syndromes; the binary search requires time:
. The companion may be determined with a binary search
over coset syndromes; the binary search requires time:
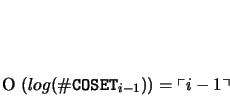
Putting everything together, we get a running time of
| O(2 | O |
| O(nm |
|||
| O(nm |
For the specific case of distance 4 lexicodes, this algorithm is particularly fast, since Brualdi and Pless [9, Thm.3.5] show that, under these circumstances:
| m = nm - 2 - |
(9) |
The analysis of Algorithm 2.12 assumes an oracle computation
of the generating mapping. For the case of lexicodes and
trellis-oriented lexicodes, however, Method 2.2 provides an
efficient means of computing this mapping in time
![]() and constant space. As in the case of
lexicodes and trellis-oriented codes, the overhead
of computing
and constant space. As in the case of
lexicodes and trellis-oriented codes, the overhead
of computing
![]() is usually eclipsed by the running time of
the remainder of the algorithm.
is usually eclipsed by the running time of
the remainder of the algorithm.
The complexity of Algorithm 2.12 is thus bounded by the co-dimension of the code and by the difficulty of computing the generating mapping. Under practical conditions, we were able to compute lexicodes well beyond length 44 initially reported in [14].
In addition, we were able to construct trellis-oriented codes with code parameters rivaling those of lexicodes, but with much better trellis state complexities. As an example, we generated trellis-oriented G-code with code parameters similar to lexicodes, but with better state complexity than the corresponding BCH codes heuristically minimized in [34]. These result were predicted by [34] and are demonstrated n Figures 2.7 and 2.8.
http://people.bu.edu/trachten
![\begin{figure}
% latex2html id marker 3488
\begin{theorem_type}[algorithm][lemma...
...emph G}_{\,i}}$\ from the newly computed coset leaders
\end{tabbing}\end{figure}](img325.png)