



Next: Bibliography
Up: Conclusions
Previous: Summary
Contents
Many problems in networking arise from the need to periodically
match up information held by hosts. Representative examples
include OSPF link state routing [34,35], Resource
discovery in networks [10], Gossip
protocols [11,36,21], QoS
routing [37,38] and Replicated
database updating [25]. These applications
often end up sending redundant information over the network in
order to synchronize similar data held on hosts. This is one of
the foremost scalability problems in these protocols - how to keep
the protocol communication overheads low while guaranteeing
accuracy and correctness.
The issue here then is to reduce the amount of redundant
information being exchanged between hosts, which makes the CPISync
algorithm an option while synchronizing host-to-host information
because the number of differences between two successive versions
of the information are typically very small as compared to the
size of the information. For example, the number of changes in
resources available on a network typically vary very slowly and so
the change in information about resources is very small between
updates in resource discovery. Attempting to employ CPISync for
these problems is an exciting extension of CPISync to network
synchronization problems.
Figure 4.1:
Simulated network usage in terms of bytes
transferred for Flooding and Name-dropper resource discovery
algorithms in a 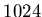 host network. The total bytes is the total
number of bytes transferred over the network. Notice the superior
performance of CPISync based Name-dropper as compared to Slowsync
based Name-dropper
host network. The total bytes is the total
number of bytes transferred over the network. Notice the superior
performance of CPISync based Name-dropper as compared to Slowsync
based Name-dropper
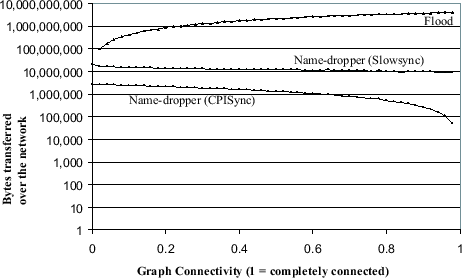 |
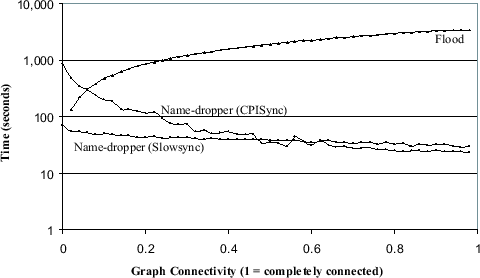
Figure 4.2:
Simulated network usage in terms of time for Flooding
and Name-dropper resource discovery algorithms in a host
network. The total time is the sum of the computation time and the
time taken to transfer the data, with the worst case bottleneck in
the network operating at 56kbps. Notice that for well connected
graphs, CPISync based Name-dropper is faster than Slowsync based
Name-dropper.
 |
As an initial incentive to explore these directions, we have
developed a simple simulator called Net sim to simulate
the amount of data transfer and the corresponding amount of time
taken to run the Name-Dropper resource discovery
algorithm [10] on a randomly generated network
topology using CPISync and Slowsync as the underlying
device-to-device synchronization methods.
The Name-Dropper resource discovery algorithm conveys information
about resources available on a network to all the hosts connected
to the network. In its simplest form, the Name-Dropper may be
employed to enable hosts to discover other hosts on the network.
Name-Dropper works like a gossip protocol in which hosts contact
their neighbors randomly to get information about their
neighbors and this continues until all the information is
propagated throughout the network.
Figures 4.1 and 4.2 shows some of the
preliminary results of our experiments. We simulated a 1024 node
random network with increasing connectivity and determined the
amount of communication (Figures 4.1) and the
corresponding time(Figure 4.2) required to complete
a Name-Dropper run. As expected, using CPISync to exchange
information between adjacent hosts resulted in considerable gains.
These experiments point to the application of CPISync to the more
general problem of device-to-device synchronization in
heterogeneous distributed networks.
A more complete PC-PDA synchronization system that can generally
synchronize PDA and PC databases is also an exciting extension to
the work presented in this thesis. It would be particularly
interesting to apply some heuristics to determine when the devices
should switch between various modes of synchronization - Fastsync,
Slowsync and CPISync for example.
Another interesting application field for the CPISync algorithm
would be in the area of synchronization network
algorithms [39] that seek to synchronize entire networks
of devices by performing successive two-host synchronizations with
the order being decided by how a data set containing the host ID
might have been sorted using various classical sorting algorithms
- the order of comparison of elements in the host ID data sets
corresponds to the order of synchronizing two hosts with those
IDs.
The CPISync algorithm itself may be improved in ways to make the
computational complexity more tangible for a large number of
differences being reconciled. Recent work suggests that the cubic
complexity (in the number of differences) of the algorithm may be
made linear using a divide and conquer approach [40].
The biggest part of the latency in CPISync synchronization is the
gaussian elimination step in order to interpolate the rational
function as was discussed in section 3.2. Any
improvements in this area will have a direct bearing on the
efficiency of CPISync.
Next: Bibliography
Up: Conclusions
Previous: Summary
Contents
Sachin Kumar Agarwal
2002-07-12