Next: Bounding Length Up: Bounding the Covering Radius Previous: Bounding the Covering Radius Contents
| a |
We proceed to the proof of Theorem 2.7.
Proof of Theorem 2.7. Following convention, we let
![]() denote the number of errors that the codes of a
G-family can correct.
It is well-known that each vector in
denote the number of errors that the codes of a
G-family can correct.
It is well-known that each vector in
![]() 2nm-1
of weight
2nm-1
of weight ![]() t must be a unique coset leader for
G m-1. Moreover, using our assumption about n0 (which also holds for
nm, since
nm
t must be a unique coset leader for
G m-1. Moreover, using our assumption about n0 (which also holds for
nm, since
nm ![]() n0), Lemma 2.8 implies
that
n0), Lemma 2.8 implies
that
| min |
|||
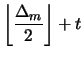 |
|||
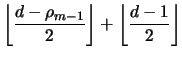 |
The result in Theorem 2.7 also applies to all
G-families trivially seeded with the code
![]() d.
d.
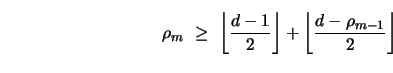
If a G-family is trivially seeded, then, necessarily, n0 = d and
![]() .Thus,
.Thus,
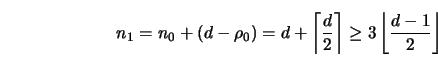
We now turn our attention to generating mappings which produce codes
whose information rate is locally maximized. More specifically, for
any code
![]() with covering radius
with covering radius
![]() , we will consider only
generating mappings f with the property that the Hamming distance
from
, we will consider only
generating mappings f with the property that the Hamming distance
from
![]() to
to
![]() is exactly
is exactly
![]() . We will call such
mappings minimal generating mappings, and the corresponding
family of codes minimal G-codes, because they locally
minimize length (and hence locally maximize information rate) for a
given dimension and minimum-distance.
. We will call such
mappings minimal generating mappings, and the corresponding
family of codes minimal G-codes, because they locally
minimize length (and hence locally maximize information rate) for a
given dimension and minimum-distance.
As an example, the generating mappings for the traditional lexicodes
and the trellis-oriented lexicodes are both minimal. We may now
easily strengthen Lemma 2.6 by observing in its proof
that
![]() = d -
= d - ![]() for minimal G-codes.
for minimal G-codes.
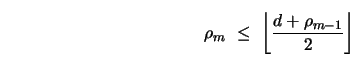
The covering radius bounds we have developed for G-codes translates naturally to length bounds as well.
 a
a