 ...researching fundamentals of networking and communications
|
Characteristic polynomial interpolation for fast data synchronizationWhat is CPISync?Available in postscript(5.7M) or pdf(372k) Many Current PDA (Personal Digital Assistant) architectures use an algorithm known as slow sync for the synchronization of a PDA with a PC. This algorithm requires a transfer of all the PDA data to the PC in order to determine the differing records between their databases. This approach turns out to be particularly inefficient, in terms of bandwidth usage and latency, as the actual number of differing entries is typically much smaller that the total number of records stored on the PDA. We have proposed, analyzed and actually implemented a novel PDA synchronization scheme termed Characteristic Polynomial Interpolation-based Synchronization (CPIsync), that relies on recent information-theoretic research results. The most salient property of this scheme is that the amount of communication needed for synchronizing the databases of the PDA and the PC relates only to their mutual differences. The basic approach taken by CPIsync is a hashing of the data into a certain type of polynomial known as characteristic polynomial. Both the PDA and the PC maintain their own polynomial. When synchronizing, the PDA sends to the PC evaluations of its polynomial at a number of random points. This number must exceed the number of differing entries. These evaluations suffice for the PC to determine all the differences, through a computational procedure known as interpolation. Our implementation shows that the computational complexity of CPIsync is affordable in most reasonable scenarios, and the time taken to perform synchronization is generally much smaller than with slow sync. The CPIsync scheme thus carries the potential for a tremendous performance improvement over current PDA synchronization protocols. Figure 1 - CPIsync scales very well as number of records in the databases increase, leading to a significant improvement over the widely used slow sync. Read a related paper S. Agarwal, D. Starobinski, and A. Trachtenberg, On the Scalability of Data Synchronization Protocols for PDAs and Mobile Devices, special issue IEEE Network Magazine: Scalability in Communication Networks, to appear July/August. Available in ps (5.5M) or pdf (973k).See How it WorksSystem Overview - A Step by step Walkthrough of the Entire SystemIn order to use the CPISync algorithm to synchronize between a PC and PalmPilot, we must make sure that the proper meta-data gets generated on both platforms and gets transmitted appropriately. The following is a step by step explanation of the entire process, from entering memo text all the way to viewing synchronized memos. Click on Figure 2 to see an illustration of the same process. 1) The User enters memo text in our specialized applications. On the PalmPilot, we have developed a MemoPad look-alike application called SyncMemo which functions almost exactly like the built-in MemoPad application. On the PC, we have developed PCMemo, which functions like the Palm Desktop's memo editor. 2) Once the memo text is saved, a 16-bit hash value is calculated based on the text (currently, a simple XOR of the even bytes concatenated with the XOR of the odd bytes of the memo text). This hash value gets added to a database containing the hash values of all the memos stored on either the PC or the PalmPilot. 3) On the PalmPilot, the new hash value is added to the characteristic polynomial, causing the characteristic polynomial to be recalculated for all sample points. The PC does not need to do this step, because it will generate its characteristic polynomial "on-the-fly" when it runs the CPISync algorithm. 4) When the User requests a hotsync, the PalmPilot sends its characteristic polynomial sample points over the network. The PC uses these as input to the CPISync algorithm, which outputs the hash values that the PC is missing that are present on the PalmPilot, and the hash values that the PalmPilot is missing that are present on the PC (1). 5) The PC finds the memos that correspond to the PalmPilot's missing hash values. The PC then sends over the network the memo texts, and the list of hash values that it is missing from the PalmPilot. The PalmPilot finds the memos that correspond to the PC's missing hash list and send over the text of those memos. It then incorporates the text of the memos that the PC sent to it (2).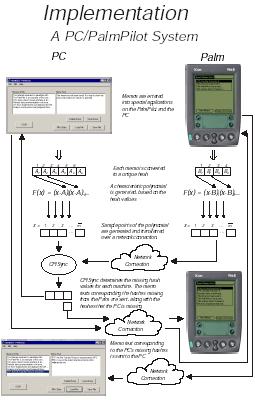 Figure 2 - A significant amount of meta-data needs to be generated before CPISync can be run. Click on the thumbnail to see a detailed view of the entire process, from entering memo text to synchronizing it. CPISync PerformanceA Breakdown of the Major Performance Issues in the SystemFigure 3 shows the performance of CPISync in the time required to synchronize with an increasing number of differences between the data sets. Each separate part of the system is colored differently, to show how much time each one takes out of the whole process. The breakdown is as follows (from least to most time consuming): 1) Misc. Tasks - These are the routine tasks that must be done in any programming environment. The cost of allocating and de-allocating heap memory as well as some informational calls to the PalmPilot are included here. 2) Characteristic Evaluations Transfer - This is the time it takes to transfer the sample points stored on the PalmPilot to the PC over the network (in this case, a 115k serial link). 3) CPISync - This is the time spent in actaul computation on the PC. Although the CPISync algorithm is cubic in the "number of differences", this really means that it is cubic in the upper bound on the number of differences (i.e. one less than the number of characteristic polynomial evaluations transferred). The algorithm is also only linear in the number of actual differences between the two data sets. 4) Missing Memo Transfer - This is the time spent in the actual transfer of the memo text both to the PalmPilot from the PC and from the PC to the PalmPilot, AND the time spent by the PalmPilot doing a lookup of the memo texts that the PC is missing (this time accounts for a majority of this block). 5) Missing Memo Incorporation - This is the time spent by the PC and PalmPilot to incorporate the new memo texts into their databases. This time block is dominated by the PalmPilot because it must update its characteristic polynomial for each new memo added, which is compuationally intensive, but still linear in the number of differences (while the PC doesn't need to maintain a characteristic polynomial).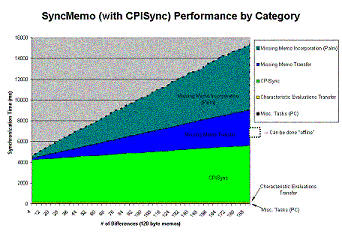 Figure 3 - Click on the thumbnail to see a breakdown of the timings of the major components of the SyncMemo system. Communication PerformanceCPISync also is linear in the number of bytes required to synchronize, regardless of the upper bound on the differences and the data set size. In this figure, we can see that the naive synchronization method, Slowsync, is not scalable in the data set size.PROBSync PerformanceAn Alternative to CPISync?Figure 4 shows the performance of a variant of the CPISync algorithm known as ProbSync. Rather than have a strict upper bound on the number of differences that it can synchronize between (as CPISync does), ProbSync starts with a small upper bound, but if unable to synchronize using that bound, it will increase the bound and use more evaluations. The upper bound on the number of differences is now limited only to the number of evaluations that the PalmPilot makes available to the PC running ProbSync. In addition, since ProbSync is simply running CPISync until it manages to confirm that it has used a sufficient number of polynomials (it can confirm this with a certain probability of assuredness, hence ProbSync) ProbSync usually takes less time than straight CPISync. This is because CPISync takes computation cubic in the size of the upper bound on the number of differences, so for small numbers of differences, ProbSync can capitalize on a much lower synchronization time. Our prototype system is designed to switch seamlessly between the two methods of synchronization. All other blocks of time in the figure are unaffected by this change in the system.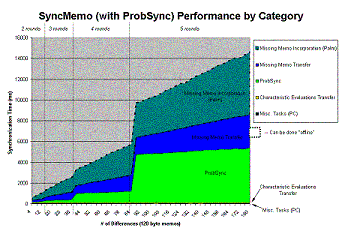 Figure 4 - Click on the thumbnail to see a breakdown of the timings of the major components of the SyncMemo system under PROBSync. DownloadUser's interested in downloading the SyncMemo project distribution should be aware of two things: 1) Our development platform is Windows. We used the generic Palm Conduit API (in C) to implement the conduits. The CPISync and ProbSync algorithms are also implemented in generic C. All Palm applications have been written for PalmOS v3.3. All PC-side software not mentioned above uses Windows technology in some way, and may not be compatible with other operating systems. We are interested in porting though! 2) The purpose of this project was to produce a prototype system. There are still a number of bugs left in the code, and users should be cautioned before committing their data to our system. Download the whole distribution here. (42.1MB) Download just CPISync here. Read the Project Report here. |
|||
Photonics Building, Room 413
8 St Mary's Street,
Boston MA 02215
Initial web site created by Sachin Agarwal (ska@alum.bu.edu), Modified by Weiyao Xiao (weiyao@alum.bu.edu), Moved to TWiki backend by Ari Trachtenberg (trachten@bu.edu). Managed by Jiaxi Jin (jin@bu.edu).