We ran the CPISync and Slowsync protocols on the
PC-PDA synchronization system for various set sizes - varying from
sets of elements to sets of elements with
differences varying from 0 to more than for these data
sets. We timed the total latency of the synchronization as the sum
of the communication time (time taken to transfer data from the
PDA to the PC) and the computational time (time taken to reconcile
the data sets), ignoring the time to upload data from the PC back
to the PDA since this is identical for both the protocols.
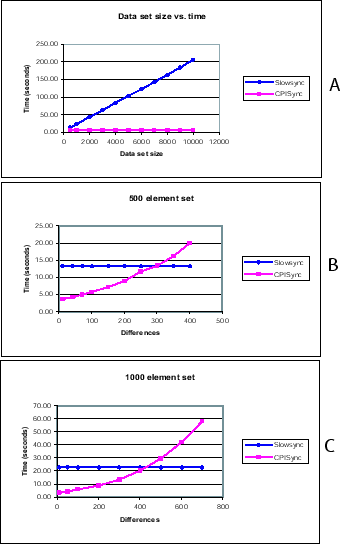
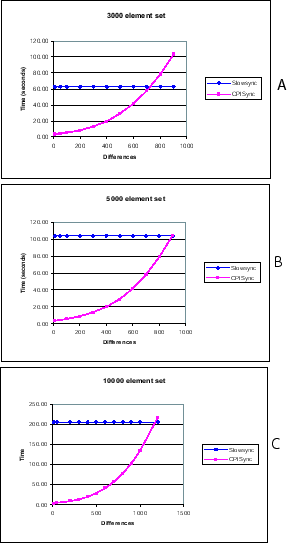
Figures 3.6 and 3.7 show some of the
data we collected. The values given are averages over trials
of identical experiments.
Figure 3.6:
(A) highlights the superiority of CPISync over Slowsync
by showing that Slowsync does not scale with increasing number of
elements in a data set and a fixed number of differences. The next
two graphs show the comparison the latency of CPISync and Slowsync
for (B) and (C) element sets and varying differences.
Figure 3.7:
These three graphs show the comparison the latency of
CPISync and Slowsync for (A) , (B) and (C)
element sets and varying differences.
Figure 3.5 (a) depicts the superior scalability of CPISync
over Slowsync. In this figure we have plotted the time used by
each synchronization scheme as a function of data set size for a
fixed number of differences between data sets.
It is clear from the resulting graphs that Slowsync is markedly
non scalable: the time taken by Slowsync increases linearly with
the size of the data sets. CPISync on the other hand is almost
independent of the data set sizes. Comparing Figure
2.3 to Figure 3.5 (a) we observe that the
qualitative behavior of CPISync is similar to that of Fastsync.
The remarkable property of CPISync is that it can be employed for
any synchronization scenario, regardless of context, whereas
Fastsync is employed only when the synchronization took place
between the same PC and the same PDA.
Table 3.1:
Threshold values at which CPISync takes the same time
as Slowsync.
Data set Size
Differences
100
161
250
175
500
253
1000
431
2500
620
3000
727
5000
899
10000
1177
In figure 3.5 (b), we compare the performance of
CPISync to Slowsync for data sets with fixed sizes but increasing
number of differences. As expected, CPISync performs significantly
better than Slowsync when the two synchronizing data sets do not
differ by much. However as the number of differences between the
two data sets increase, the computational complexity of CPISync
becomes significant. Thus, there exists a threshold where
wholesale data transfer (Slowsync) becomes a faster method of
synchronization; this threshold is a function of the data set
sizes as well as the number of differences between the two data
sets. For the record sets depicted in the figure, this
threshold corresponds to roughly differences.
By preparing graphs like Figures 3.6 and
3.7 for various different set sizes, we are able to
produce a regression with coefficient of
determination3.1 [33] almost that
analytically models the performance of Slowsync and CPISync. The
resulting threshold values are listed in Table
3.1. The regression for Slowsync is obtained
using Maple by fitting the data to a linear function that
depends only on the data set size, where as for CPISync the
regression is obtained by fitting the data to a cubic polynomial
using Maple that depends only on the number of
differences. Note that in a PDA application like an address book
or memo, changes between concurrent synchronization typically
involve only a small number of records. For such applications,
CPISync will usually be much faster than Slow Sync.
In Table 3.2, we show the fitted cubic polynomials
generated using Maple corresponding to , ,
, , , and element data sets for
the total time(latency) with parameter (differences). It is
interesting to note that for a small data sets (and consequently
small differences), it is the communication time which seems to
dominate and the cubic fit is not good, whereas for sets of size
or more, the cubic computational complexity dominates the
total latency. The communication time is dependent on the
operating systems on the PDA and the PC and there was a high level
of inconsistency observed in the timing (of the order of ) even though all these results have been averaged out over
trials. In the table, we see there is an overhead of about
seconds (constant term coefficient) which corresponds to the
setup time of the protocol and other operating system overheads.
For bigger size sets (), it is interesting to note from
Table 3.2 that the highest order (cubic)
coefficient is almost the same irrespective of the number of
elements in the set. This again shows that CPISync is not
dependent on the size of the data set. In fact, for big data sets
with considerable differences, the latency may be represented by
any one of the polynomials in Table 3.2, since for
large values of the cubic term dominates the value of the
latency. We shall use this fact to model an optimal Probabilistic
scheme in section 3.3.
Table 3.2:
Fitted polynomials for CPISync running time
for various data set sizes.
Data set Size
Fitted Cubic Polynomial
100
250
500
1000
3000
5000
10000
The implementation of CPISync described here requires the
knowledge of a tight upper bound
, on the number of
differing entries. One simple method for obtaining such a bound
involves having both hosts and count the number of
modifications to their data sets since their last synchronization.
The next time the hosts synchronize, host sends to host a
message containing its number of updates, denoted
. Host uses its own value
to
compute
which is
the upper bound on the total number of differences between the two
hosts. Clearly, this bound
will be tight if the two
hosts have performed updates to mutually exclusive records.
However, they may be completely off if the hosts have performed
exactly the same updates to the same records in their databases.
This may happen if, prior to synchronization, both hosts A and B
synchronized with a third host . Another problem with this
method is that it requires maintaining separate information for
each host with which synchronization is performed; this may not be
reasonable for large networks. Thus the simple method just
described will be rather ineffective for some applications.
In the next section we describe a probabilistic scheme that can
determine a much tighter value of
. This result is
of fundamental importance as it means that, in a general setting,
both the communication and computational complexities of CPISync
depend mostly on
.
Next:Probabilistic CPISync Up:Deterministic CPISync Previous:Metrics and MeasurementsContents
Sachin Kumar Agarwal
2002-07-12